在数字化时代,语音助手正逐渐成为我们日常生活和工作中的得力助手。为了使语音助手更加个性化,以及提供更好的用户体验,越来越多的研究者和开发者开始尝试使用电脑语音克隆技术。本文将为您介绍一套完整的电脑语音克隆开发教程,帮助您了解并掌握这一领域的基本步骤和技巧。
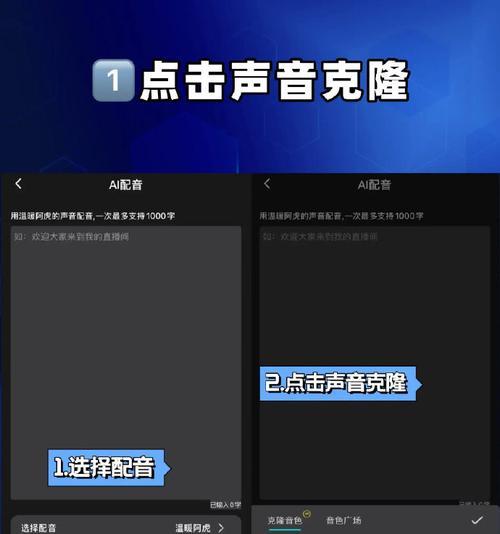
准备工作:搭建语音克隆开发环境
在进行电脑语音克隆开发之前,我们需要搭建合适的开发环境。安装并配置深度学习框架,如TensorFlow或PyTorch。安装相关的语音合成工具,例如WaveNet或Tacotron。下载并准备好用于训练的语音数据集。
数据预处理:清洗和标注语音数据
准备好的语音数据集通常会包含大量的噪音和无效信息。在进行模型训练之前,我们需要对数据进行清洗和标注。清洗数据包括去除噪音、归一化音频质量等操作,而标注数据则是为每个音频样本添加相应的标签,以便训练模型时能够正确识别和生成语音。
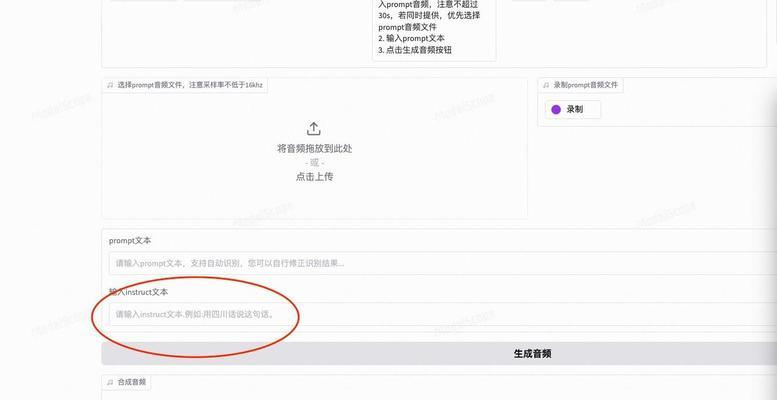
搭建模型:选择合适的深度学习网络结构
在语音克隆开发中,选择合适的深度学习网络结构是至关重要的。常用的模型包括循环神经网络(RNN)、卷积神经网络(CNN)以及变分自编码器(VAE)。根据自己的需求和数据集特点,选择适合的模型并进行相应的配置和参数调整。
训练模型:使用语音数据集进行模型训练
经过前期的准备工作,我们可以开始使用准备好的语音数据集对模型进行训练了。通过将数据输入到模型中,并反复迭代优化模型参数,使得模型能够更好地学习到语音的特征和生成规律。
优化模型:调整模型参数和超参数
在训练过程中,我们可能会发现模型在一些方面表现不佳,例如语音质量不高或生成不自然。这时,我们可以通过调整模型的参数和超参数来优化模型的性能。常见的优化方法包括学习率调整、正则化、批归一化等。

验证模型:评估语音生成效果
在模型训练完成后,我们需要对生成的语音进行评估,以了解模型的性能。常用的评估指标包括语音质量、语音流畅度和发音准确度等。根据评估结果,我们可以进一步调整模型并重新训练,以提高生成语音的质量。
语音合成:将文本转换为语音
除了生成个性化语音外,我们还可以使用训练好的模型将文本转换为语音。通过将输入的文本序列经过模型处理,生成相应的语音输出,实现个性化的语音合成功能。
应用场景:语音助手、影视配音等
电脑语音克隆技术可以应用于各种场景中。其中,最常见的就是个性化语音助手。通过将模型嵌入到语音助手中,可以为用户提供个性化的回答和服务。此外,电脑语音克隆还可以应用于影视配音、游戏角色音频生成等领域。
挑战与解决:克服语音合成中的问题
在电脑语音克隆开发过程中,我们可能会面临一些挑战和问题。例如,生成语音的质量不高、语音流畅度不够自然等。这时,我们可以通过调整模型结构、增加训练数据、采用先进的语音合成算法等方法来解决这些问题。
未来发展:向更智能的语音助手迈进
随着深度学习和语音合成技术的不断进步,电脑语音克隆将会越来越普遍,并且变得更加个性化和智能化。未来,我们有望看到更加逼真、自然的语音助手,并且能够实现更多的交互功能。
结尾
通过本文的介绍,我们了解了电脑语音克隆开发的基本步骤和技巧。从搭建开发环境到训练模型,再到优化和应用,每个阶段都需要我们仔细思考和调整。希望本文对您在电脑语音克隆开发方面有所帮助,并能够为您打造出个性化的语音助手。